
Updated! Now supports nVidia’s ShaderPerf tool.
Downloads
EffectCompiler.zip [51.3kb] – XNA Game Studio Express 2.0 (Visual C# 2005 Express), Source + Binaries
Description
Yesterday I took apart my Effect Compiling Tool which took a HLSL shader and converted it to Windows/Xbox360 bytecode, and made it into something more useful outside of XNA.
It’s always been somewhat of a hassle for me to compile and disassemble HLSL shaders. I can edit them pretty well in Visual Studio with code coloring and tabulations/undo’s/whatnot, but to compile them I always had to go with something else. I had read in the book Programming Vertex and Pixel Shaders by W.Engel how to compile them in VC++ 2005 using a Custom Build Step and fxc.exe, but when working in C# I had to have a parallel C++ project just for shaders, which is dumb. Also, fxc.exe has become less and less stable for some reason… So I finally made my own compiler and disassembler using XNA 2.0.
Here’s what it looks like (very similar in layout to the XNA Effect Compiling Tool) :
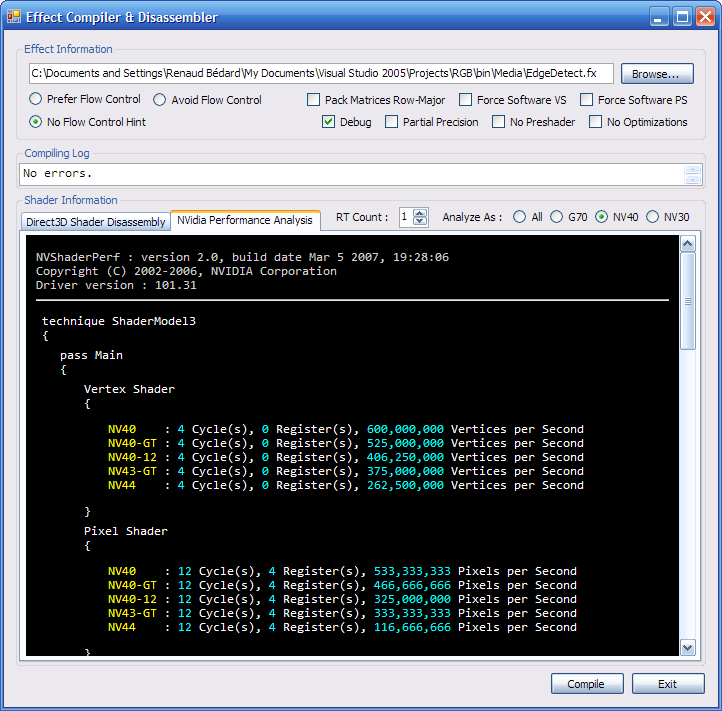
So usage is as simple, you browse for your shader script, tick the compiler options that you want, and compilation & disassembly occurs.
Just like its ancestor, it supports #include directives in the shader (which I adore and encourage to use) and should play well with just any shader.
The disassembly frame is actually a web browser because the Effect.Disassemble() XNA static method returns HTML markup. So I save into a temp file and with a WebBrowser control I navigate to it.
I really think of disassembled shaders as an essential tool in HLSL programming because it allows you to see how the compiler has been able to optimize your code, and how much instructions you have left. With “Debug” ticked as a compiler option, you can see which lines and files are referred by which instructions, and so keep track of the compiler’s line of thought.
I currently use this tool for a TV3D project, since Visual Studio for shader editing and this tool for compiling and disassembly is a much more efficient production pipeline than the SDK’s Simple FX Editor in my opinion.
Try it and see!
Update notes
Following Daniel’s suggestion, I added support for nVidia’s ShaderPerf tool, which profiles HLSL code to know the number of cycles and vertices/pixels per second that each GPU model effectively does. This can be useful for optimization.
Besides, nVidia’s CLI tool is pretty hard to use since it asks to choose whether you want to profile the vertex shader or the pixel shader, then asks for the technique and pass you want to profile… So my interface simplifies the process and asks the performance data for each pass, each technique and for both VS and PS.
It also formats the information in a very succinct way, and gives it a similar look to the D3D shader disassembly.
One problem is that I can’t redistribute the tool as per nVidia’s license. So you’re going to have to download and install it yourself, and the app looks in the default install path (in the host machine’s Program Files folder) to find the executable.
If for some reason that fails, you can throw the .exe in my tool’s binary path, and it’ll look there as well.
NVIDIA ShaderPerf 2 Alpha download site.
I did try using ATi’s similar tool called “GPU ShaderAnalyzer”, but its command line interface is even more cryptic than nVidia’s, and I gave up using it after trying for an hour or so. If anyone can point me to an example usage, I’d be glad to add it to my app!
Enjoy!
This is bullshit because anybody can achieve such results by writing just two lines of C# code…
The whole point of me making and posting this is not having to make it yourself! It’s a TOOL.
If it’s not useful to you, just don’t use it.
It may take only two line of C# code to get the dissasembaled code, but thats very different to wrapping it all up in what looks like a nice easy to use tool. Good work, if i ever make the jump to 3d, ill deffinatly check it out!
Very cool. It would also be interesting to plug this into ATI and Nvidia’s tools to get real performance numbers (dx asm is just an intermediate language, it gets optimized by the driver when you call Create*Shader so the number of cycles used to execute the shader != the number of dx asm instructions).
@Daniel : Great idea! I just implemented the nVidia command line tool into the interface yesterday, and once I understand how to use ATi’s from the CLI I’ll put it in as well.
If it just never works I’ll post it as-is, better than nothing…
Hi Renaud,
I really liked your Effect Compiler and Effect Compiling Tool. Although they are simple tools they are very handy.
I would like to suggest that you merge both tools, or in other words, add the bytecode generation and “Copy To Clipboard” features to the Effect Compiler.
Thank you very much for this app! Just started to analyze asm code mainly for understanding how many instructions are generated (depending on the order of operations you could trigger dot products or madd ops, didn’t know that).
This app makes it really easy to iterate several times, just select a file and click compile, change some settings and then click compile again…
Also I support this kind of efforts, this makes it so easier to see rather than messing around with command lines windows, and then opening another file to see what was the output. It is also NOT TWO LINES of code…
I would like to ask though (this is still way beyond my knowledge) what is the preshader section of the compiled effect? In my shaders I have way too many instructions, sometimes even more than 50 preshader instructions. Are these state settings? sampler settings? The name “pre-shader” can be literally interpreted like that? runs before anything and hence it may be 100 instructions but forgettable since 5 vertex with 20 instructions will take the same amount.
Thanks again.
@Alejandro : That’s awesome, thanks!
So about the preshader section… They’re instructions that are detected by the HLSL compiler to be only tied to semantics and not to texture reads or interpolated registers, so they can be calculated once per pass instead of for each pixel/vertex.
What happens is that the CPU (I don’t know why not the GPU, but that’s what I’ve read everywhere) parses the preshader before the mesh gets rasterized, and sends the data in the appropriate registers.
And instructions in the preshader don’t count in the instruction limit since they’re done by the CPU beforehand.
Hi Renaud! Thanks for your response!
Excuse me for my late one…
Got it!
But in general should we avoid preshaders? I mean, do they stall the gpu in any way?
Some questions:
1. Should I worry about it?. (I.e. Try not to be extremely lazy and fix those that are instantly fixable)
2. Is this related to shader patching? To tell you the truth, I have been seeing this lately, but never been able to find a formal definition of it. Only “Avoid shader patching”, or “Shader patching = nastiness”. (Is this even avoidable on XNA?)
Excellent blog by the way, liking it a lot!
1. No, I’d say preshaders are a Good Thing(tm)… it keeps the constant data out of your shaders at runtime, without you needing to extract the logic out to your application code. You don’t want to jump through hoops to avoid the compiler from generating them. I haven’t heard anything about stalls induced by them.
2. I hadn’t heard about patching before now… If it’s what this post refers to (http://c0de517e.blogspot.com/2008/04/gpu-part-1.html), then it’s about vertex texture fetch and parallelism inside the GPU… I doubt it’s related to preshaders but I wouldn’t know how to avoid it.
And thanks! :)
Would like to comment on something that Shawn Hargreaves posted on his blog. As it is of insterest in the comments that took place here.
http://blogs.msdn.com/shawnhar/archive/2010/04/25/basiceffect-optimizations-in-xna-game-studio-4-0.aspx
The preshaders that we were discussing, that you pointed out as that they are a good thing (as indeed they are!), are not (grab yourself) supported on the XBOX!! (nor the incoming Windows Phone).
This renders this little app you made as a permanent opened application whenever I’m coding some stuff. This just explain why some things would become so slow on the xbox for me, due to lack of knowledge in shader algorithms, tricks, trying to pack all in one vertex shader, etc I have had preshaders of more than a 100 sometimes 200 preshader instructions…
There goes using World View and Projection Matrices separately, now it should be a single preconcatenated WVP matrix.
Oh my, here comes more shader permutations.
Oh wow, this comes as a big surprise to me. Time to optimize all of Fez’s shaders…
I don’t get it though. The Xbox is supposedly a next-gen platform, and preshaders are standard in the HLSL compiler since Shader Model 2.0, which the Xbox fully supports and has extensions to. WTF??!
Totally shocking indeed…
However the xbox shaders are xps 3.0 and xvs 3.0, and maybe it is not as easy or mature to optimize/compile. Also they will always compile to that format independently
1. I was always intrigued that to actually unroll a loop on the xbox you need to specify a [unroll(COUNT)] attribute right before calling the iterator, normally, the fxc compiler will unroll it for you… This made me redo all does gaussian and other blurring shaders manually unrolled to avoid confusions that depends on target platform, so if a loop is unrolled the compiled shader WILL BE unrolled for each platform, and not dependent on compilers luck/heuristics or xbox’s attributes.
2. With this in mind, how do we know then that we are getting the most of shader compiler optimizations? When checking the “No Optimizations” and “No Preshaders” checkboxes of your application, even some of the simplest shaders will yield sometimes more than twice the instruction/textures slots !!!!.
The compilers are just way too damn aggressive with this, getting a value and doing something with it in the next line of code, the compiler will rely on some asm instructions, separating channels, vectors, etc something maybe not humanly possible to do… even cleverly packing data, taking advantages of dp4’s instructions to add up 4 vectors at once, branch testing four values at once (float4 a = float4 b > float4 c ? float4 r1 : float4 r2;), and everything you could think of to please the gpu, the compiler will go several steps further, reorganize your code, hide latencies, move variables, and hell… it’s an EYE OPENER.
I definitely have to do more research on this to confirm these doubts, I mean if there are no preshaders (something that as you pointed out, are standard as of Shader Model 2.0), you could make hypothesis on everything else.
3. Shawn Hargreaves points out that a new method for effects is implemented to circle around the pre-shaders thing (a new OnApply() overridable method for Effects). Don’t understand how it would work, I have already asked in the blog.
Do optimize those shaders where you need them! Even if it is bad news, at least it always good to know that there is some new room to give to your game, hopefully the last push it would need…
Fez looks incredibly good! Those “trixels” are just sick, and the way they were implemented gameplay wise blew my mind… the soundtrack is mind blowing too!.
I’m pretty sure the compiler can make a much better job at optimizing anything from a C program to HLSL, but there’s always ways to hint it in the right direction… by using pseudo-attributes and just ordering the logic as it expects it.
About OnApply(), I’m inclined to think that it’s just a callback method that allows you to fill per-pass uniform variables at the “right time”, since XNA GS 4.0 doesn’t force you to Apply() shaders by hand (there’s other higher-level ways of mapping shaders to geometry).
So if you can manage to fill up those variables once per “Apply” and emulate those pre-shaders, you’ll effectively have the same performance in the end.
And thanks for the Fez praise! The main shader already has 140-ish VS instructions instead of 180-ish… :D