
(Part one is here.)
You know, I was so confident when writing the first post that I was addressing a common problem (which is not entirely untrue considering Google hits) and that it would be a pretty straightforward “here’s the issue, here’s the fix, enjoy” scenario.
Boy, was I wrong.
The common approach when trying to fix a bug is to first reproduce the problem. While I had no difficulty making a fictitious test case that does reproduce the “unreachable hashed entry” issue, I’m having all the trouble in the world finding a proper, real-world, justifiable algorithm that needs a hash table with mutable keys.
It just never seems to me like a reasonable thing to do.
Nevertheless, being the stubborn bastard that I am, I’ll present here a recipe to encounter the problem with as much justifications as I could make up. And if ever you’re ever stuck in a situation where you do need a hash set to react properly with mutable entries, well you’ll have a solution of sorts.
Take a deep breath (this is a looooong one) and hit the jump.
Note : For now, I’ve limited the scope of the problem to hash sets and not maps.
Initial situation
- There is a type A, with a named instance Ay
- There is a type B, its instances will be referred to as Bees (singular: Bee)
- Ay has a collection of Bees named AyzBees
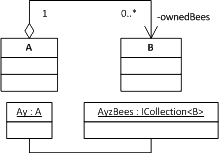
Very simple for now. And a very common situation, just any two classes with an aggregating association would qualify.
Choosing a collection type
I’ll want to end up with AyzBees being a set. But why would one choose to make any collection a set? Here’s a list of all the possible motivations I could think of :
- Bee duplicates inside AyzBees are illogical
- Set operations (union, intersection, difference,…) would be useful in A‘s algorithms
- B has a (preferably small) subset of attributes that uniquely identifies a Bee, Bees do not need a surrogate identifier (e.g. for storage) and it would be superfluous as part of a Bee‘s definition
So that covers sets, but why a hash set in particular? Possible motivations…
- Containment detection, insertion, deletion or lookup of a Bee inside AyzBees must be fast
- Bees are not comparable to one another (i.e. Bees do not have a total order)
- Bees are comparable, but keeping AyzBees sorted is not useful
Typically, all operations mentioned in the first point are executed in constant time in a hash set, so very fast and non-depending on the number of items in the set.
So we’re set (ha, ha.), we’ve chosen a hash set for all or some of the above reasons. This imposes us the following constraints :
- AyzBees will not contain duplicates
- The enumeration order of AyzBees will be unpredictable
- B must have a subset of attributes that uniquely identifies a Bee
This may sound redundant, but instead of just motivating our choice of collection type, those are restrictions we can’t do anything about, they’re inherent to the usage of a hash set. So we’d better double-check it works with our case.
Additionally, in C#, B must override object::GetHashCode() and object::Equals(object) to be identified inside hash sets by its attributes.
Mutability
The simplest situation is a set of wholly immutable elements. This way we’re sure that the identifying attributes of any won’t change, because the whole objects cannot change. But why wouldn’t we want that?
B cannot be a value-type (i.e. struct) nor an immutable class (doesn’t exist as-is in C# but can be enforced) if it has at least one attribute which :
- Does not uniquely identify a Bee instance
- Cannot be deduced directly from its identifying attribute(s)
- Is proper to a Bee instance (i.e. functional dependency between it and the identifying attribute(s))
- Is mutable, nothing logically restrains it from changing
But even if B is a mutable class, if its identifying attributes are read-only and immutable, the hash code never changes. But let’s pretend we can’t do that; we need B to have mutable and/or writable identifying attributes.
This is where I’m having lots of trouble justifying the eventuality. But here goes… possible motivations for having mutable/writable identifiers :
- Bee instantiation is costly (e.g. slow, resource-consuming) or non-desirable, it is preferable to mutate current instances
- AyzBees is made an immutable set (i.e. cannot add or remove items, but can mutate them) after being filled
That’s all I could come up with.
And I have yet to find an algorithm which requires any of those, and where the requirement isn’t mere laziness.
The final situation
To sum it up, here’s what the final situation looks like as an UML class diagram :
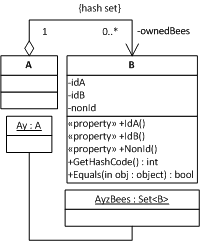
The UML notation omits a lot of information mentioned above, so it isn’t really complete, but it’s better than nothing.
By using my invented «property» stereotype, I assume read-write properties (both getter and setter), so that enforces writability. Also I don’t use .NET 3.5’s HashSet<T> because I haven’t worked with C#3.0 yet, so I refer to the PowerCollections’ Set<T> class which I know uses hashing.
The Problem
The problematic series of operation is the following :
- A Bee is added inside AyzBees
- The same Bee is mutated to alter one or more of its identifying attributes
- We do a deletion, containment test or any similar operation that implies passing of the mutated Bee to AyzBees
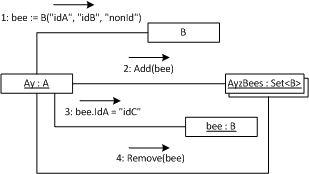
Since we’re always operating on the same object, logically, the third operation should work.
But when adding an object to a hash set, its hash code is used as a key to find which slot it’ll be stored in. And whenever you try to access that same object, it’ll try to find it using the supplied object’s hash code, and then testing equality of all consequent slots until found.
Even if we supply the same object in terms of memory, the hash code has changed along with the identifying attributes, and so the set acts as if it’s a foreign object.
Furthermore, the object will appear when enumerating the set’s contents, so it’s definitely inconsistent behaviour.
Manual Rehashing
My first solution to fix this is to ask the host set to re-hash a freshly mutated Bee from inside its setters :
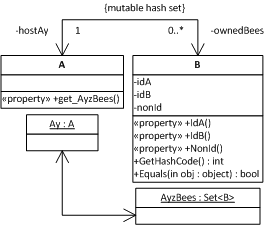
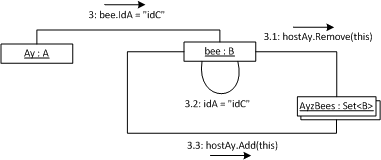
- B has an association with A (backpointer/binary association), A exposes AyzBees to B, such that a Bee has access to the set which contains it
- Every one of B‘s identifying attribute mutators (i.e. setters) remove the current Bee from its host set (in this case AyzBees) prior to mutation, and re-add after mutation, thereby forcing a rehash of the Bee and fixing the problem
This works fine, but has its share of limitations/problems :
- B‘s identifying attributes must be immutable classes or value-types, or every Bee must know when they mutate by getter access
- Probably does not make sense design-wise : unnecessarily increases coupling and complexifies both A and B‘s public interfaces
- If Bees are part of other hash tables than AyzBees, maintaining a backpointer inside a Bee to every set is a bit ridiculous
- If AyzBees is an immutable set, this pattern cannot work (cannot add or remove elements)
- Cannot mutate the identifiers of Bees while enumerating on AyzBees (will cause a “Collection was modified” InvalidOperationException)
So as you can imagine, this isn’t the solution I propose. But it’s based on that.
And since this post is getting ridiculously long, I’ll keep the solution for a third part, and I’ll join a C#2.0 test case along with it!